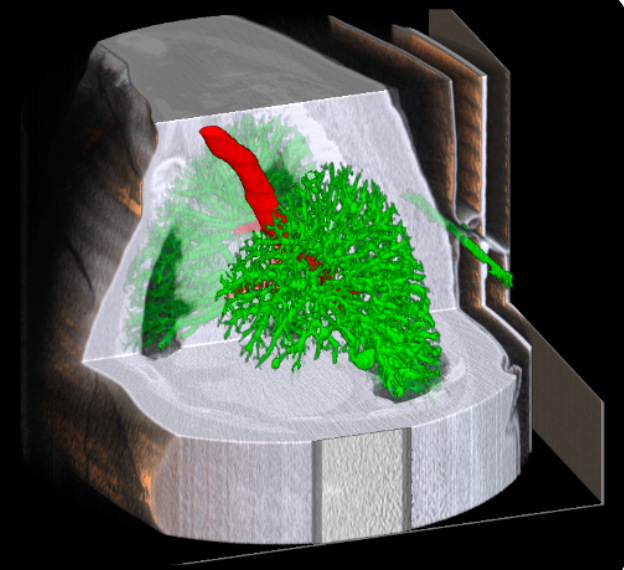
Introduction
Accurate segmentation of airways and vessels in lung CT scans is essential for diagnosing pulmonary diseases, planning treatments, and advancing medical research. Traditional image processing techniques often struggle with the anatomical complexity of the lungs, which motivates the use of deep learning-based approaches.
In this project, conducted as part of our final-year research work, we explored U-Net, UNTER, and Transformer-based architectures for airway and vessel segmentation. Two different datasets were used: one provided by our institution in .nii CT scan format, and the publicly available AIIB23 and Aeropath datasets. Our experiments highlight the performance improvements achieved by these models, supported by visual and quantitative results.
Methods
U-Net: Convolutional Neural Network for Segmentation
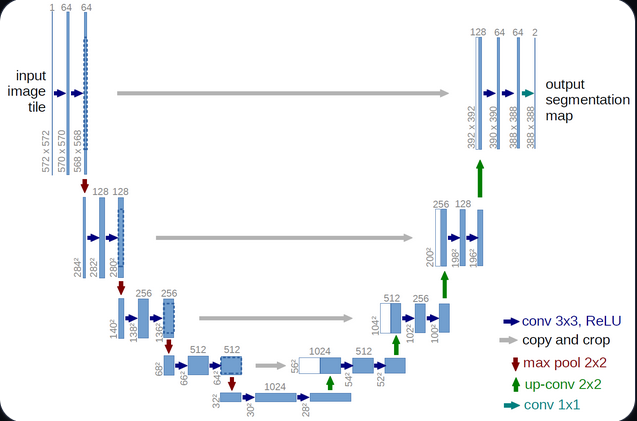
The U-Net architecture is one of the most popular convolutional neural networks (CNNs) for medical image segmentation. Its encoder–decoder structure enables the model to capture both contextual information and fine spatial details, thanks to the use of skip connections between corresponding layers.
Architecture overview:
- Encoder: A sequence of convolutional and pooling layers that progressively extract hierarchical and semantic features from the CT slices, reducing spatial dimensions while increasing feature depth.
- Decoder: A symmetric set of upsampling and convolutional layers that reconstruct the segmentation mask at the original resolution.
- Skip connections: Link encoder and decoder layers at the same level, preserving fine-grained details and enabling precise boundary reconstruction.

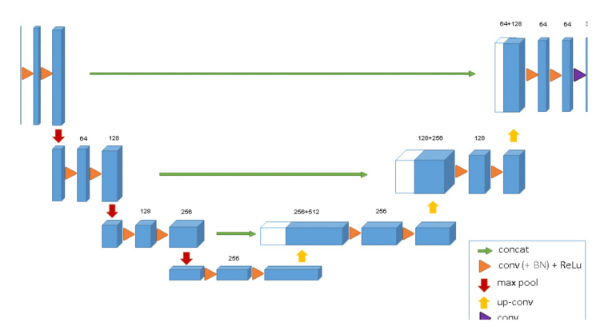
U-Net 3D: Extending U-Net to Volumetric Data
To better handle the 3D nature of CT scans, the U-Net 3D variant replaces 2D convolutions with 3D convolutions, allowing the model to learn spatial dependencies across multiple slices simultaneously. This results in more coherent and anatomically consistent segmentations in volumetric medical data.
UNTER: Enhanced CNN with Transformer Layers
UNTER combines the strengths of CNNs and Transformers. While the CNN encoder captures local spatial features, the Transformer blocks model long-range dependencies within the image, providing a more global understanding of the anatomical context.
Key components:
CNN Encoder: Extracts fine-grained and localized features from the input CT scans.
Transformer Layers: Capture relationships across distant regions of the lung, enhancing robustness to noise and improving recognition of thin vessels and branching airways.
Decoder: Reconstructs the segmentation mask by merging multi-scale contextual information from both CNN and Transformer layers.
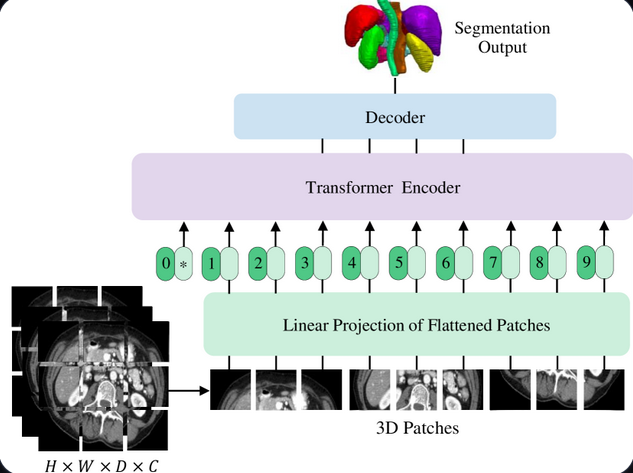
Performance: UNTER demonstrates improved segmentation accuracy in complex lung regions and greater robustness to CT artifacts compared to standard CNN-based models.